

43 min read
The translation industry has undergone a seismic shift in recent years. So much so that what we used to know as "language service providers" are now...
7 min read
03/11/2025
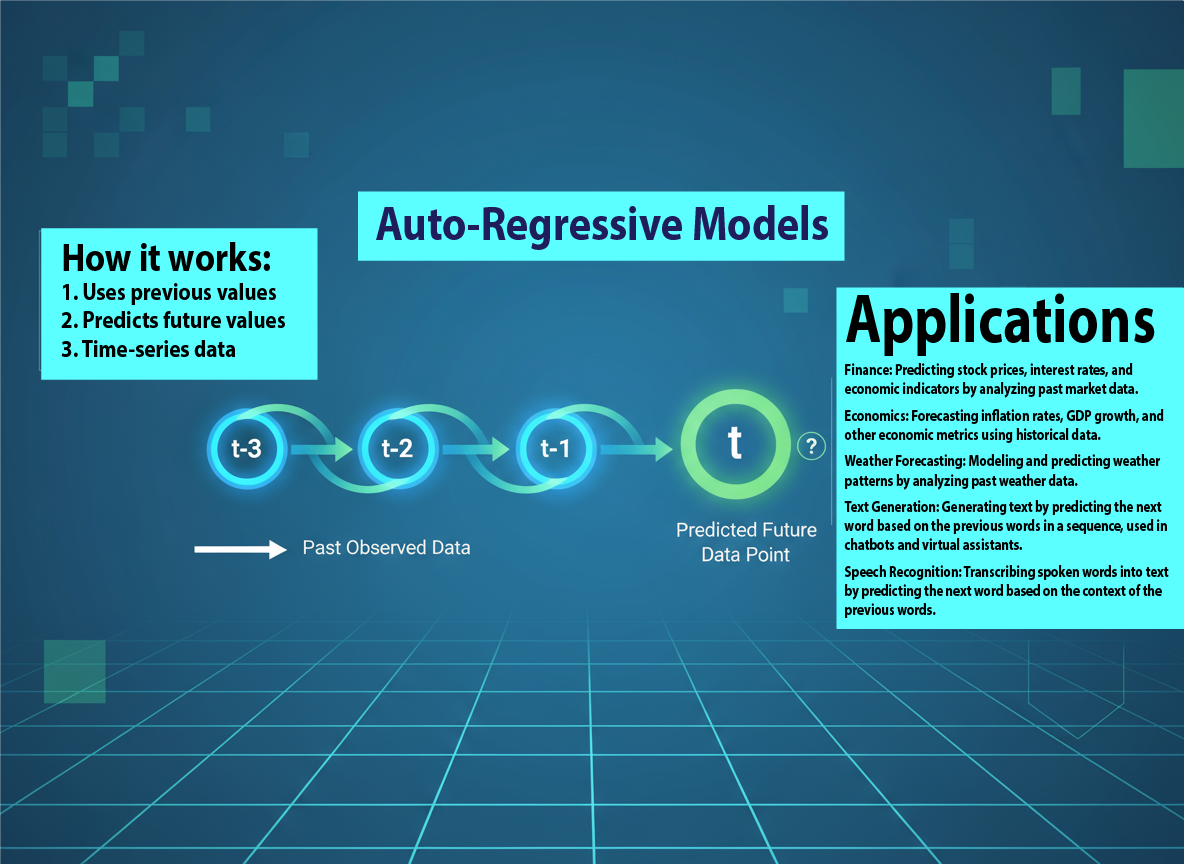
If you have used ChatGPT, Claude, DeepSeek (not trained on $5M), Gemini, or any modern public and not private Generative AI tool to write an email, summarize a report, or translate a document, you have interacted with an auto-regressive model. I'd like to explain this concept in today's blog post so users understand what is behind the technical jargon: the fundamental engine driving the most advanced artificial intelligence in history.
We will provide an authoritative, deep dive into what autoregressive models are, how they work, why they are different from other models, and how they power the services you use every day.
As a leader in AI-driven language technologies, we at Pangeanic believe that understanding this core technology is essential for any business and decision-makers looking to harness the power of Generative AI and not become part of the 80%-90% "AI implementations that fail" according to McKinsey and Gartner. Forbes reported similar rates in 2024 because of quality data-for-AI training issues.
At its simplest, an autoregressive model is a type of AI that generates new data by predicting the next step in a sequence based on all previous steps.
Let's break down the word:
In essence, the model is performing a "regression on itself." It looks at the sequence it has already produced and asks, "Based on everything I've said so far, what is the most probable next token/word?"
Think of it as an expert storyteller writing a sentence:
In reality, this is practically all the magic of the basic concept. This step-by-step, sequential generation is the defining characteristic of an auto-regressive model. What you build on top of it (things like chatbot systems, new data inputs crawling the web, speech recognition and conversations, chat history, projects, document uploads for reference in an ad-hoc RAG system, etc.)... they are all computer engineering.
And as with all computer engineering, it can be replicated.
While the concept is simple, the mechanism is incredibly complex, powered by the Transformer architecture, specifically the "decoder" part. You can find out about Transformers in our 2023 post "What Are Transformers in NLP: Benefits and Drawbacks".
This is a simplified breakdown of the process:
The mathematical idea is to model the probability of an entire sequence, P(x), by factoring it into a chain of conditional probabilities:
In plain English, the probability of a whole sentence is the probability of the first word, times the probability of the second word given the first, times the probability of the third word given the first two, and so on.
A common source of confusion is the distinction between autoregressive (AR) and autoencoding (AE) models. Understanding this distinction is key to understanding the AI landscape and the potential application of AI at an enterprise level, for example, in adaptive automatic translation, as recently completed by Pangeanic in July 2025.
|
Feature |
Autoregressive (AR) Models |
Autoencoding (AE) Models |
|
Example |
GPT-4, Gemini, Claude, DeepSeek, etc. |
BERT, RoBERTa |
|
Primary Goal |
Generation (Creating new, coherent text) |
Understanding (Analyzing existing text) |
|
How it "Sees" Text |
Unidirectional: Sees only the past (tokens 1 to t-1) to predict the future (token t). |
Bidirectional: Sees the entire sentence at once (past and future) to understand context. |
|
Core Task |
"Predict the next word." |
"Fill in the blank." (Masked Language Modeling) |
|
Analogy |
A novelist writing a story one word at a time. |
An editor reading a full paragraph to find a missing word. |
At Pangeanic, we leverage both types of models. Autoencoding models are excellent for tasks such as sentiment analysis, document classification, and Named Entity Recognition (NER). Auto-regressive models are the powerhouses we use for our generative services, but with a crucial layer of control.
Autoregressive models are widely used in many fields because of their ability to predict future values from past observations. Here are some typical applications of autoregressive models:
The auto-regressive principle is the foundation of nearly all modern Generative AI. These applications demonstrate the versatility and effectiveness of auto-regressive models in various domains, making them a valuable tool for data analysis and prediction, with an inherent risk of hallucination as part of their predictions: its greatest strength (creative, sequential generation) is also its greatest weakness for professional use.
Now we begin to understand that standard autoregressive models have significant limitations for high-stakes enterprise applications, and that we need to realistically assess what can be done and what cannot, set expectations, and define clear, achievable KPIs and step-by-step implementation plans. That is, small pilots in controlled environments. Some of the limitations that need to be taken into account are:
This is unacceptable in sectors like healthcare, pharma, legal, or finance, where a single incorrect term can have massive legal or financial consequences.
I have followed Yann LeCun's take on AI the LLM fever for years. For those who are not familiar with the "who is who" in AI, Yann LeCun is Turing Award and currently Meta's VP President and Chief of AI). He is a prominent figure in artificial intelligence, recognized for his significant contributions to deep learning and along with Geoffrey Hinton and Yoshua Bengio, was awarded the coveted award in 2014 (the highest honor in the field of computer science). I quoted him on several occasions and presentations over the last few years, to the dismay of many.

Yann believes that auto-regressive Large Language Models (LLMs) are a fundamentally flawed approach to achieving higher artificial intelligence or AGI (Artificial General Intelligence). He argues they are incapable of true reasoning and understanding, and has actively advised against working on them, pointing instead to alternative architectures like world models.
I've summarized Yann's core critique against auto-regressive LLMs and the alternative path he advocates.
|
Aspect |
Yann LeCun's Critique of Auto-Regressive LLMs |
Proposed Alternative |
|
Core Problem |
Inherently Flawed Architecture: Token-by-token generation leads to exponentially compounding errors, making long, coherent, and correct responses improbable.[1], [2] |
World Models: Systems that learn an internal model of how the world works through observation, similar to humans and animals. |
|
Key Limitations |
Lack of Reasoning & Planning: LLMs are purely "reactive" (System 1 thinking) and cannot engage in deliberate reasoning, planning, or imagine the consequences of actions.[3], [4], |
Joint Embedding Predictive Architecture (JEPA): A non-generative model that predicts in an abstract representation space, learning the dynamics of the world without getting bogged down in unpredictable details. |
|
Poor Understanding of Reality: Trained only on text, a low-bandwidth and discrete data source, they lack a grounded understanding of the physical world that a child learns through vision and interaction. [5] |
Hierarchical Planning: Breaking down complex tasks into manageable sub-goals, a capability current AI systems lack but is essential for human-level intelligence. |
|
|
Unreliability & Uncontrollability: They "make stuff up" (hallucinate) and cannot be made reliably factual or safe for critical applications. |
Energy-Based Models (EBMs): A framework where the model learns to minimize a cost function, making systems more controllable and aligned with specified objectives. |
|
|
His Direct Stance |
"Auto-Regressive LLMs are doomed". He has stated, "Don't work on LLMs," and that "from now on 5 years, no sane person will use auto-regressive models". |
He is pursuing this vision at Meta with models like V-JEPA for video understanding, aiming to create AI that can learn how the world works from observation alone. |
LeCun's position is a fundamental challenge to the current AI mainstream. His arguments suggest that simply scaling up existing LLMs will not lead to human-level AI, as I recently commented on. Instead, he envisions a shift towards architectures that can learn from vast amounts of sensory data (like video) to develop common sense and a practical understanding of reality, which he sees as the proper foundation for intelligence. Now, this is one side of an ongoing scientific debate. Other prominent researchers and companies continue to invest heavily in LLMs, and some research, such as a DeepMind paper, argues that auto-regressive LLMs are computationally universal.
At Pangeanic, our two decades serving law enforcement, government, and enterprise clients have taught us that AI is a powerful tool, not a magic solution. Auto-regressive models represent remarkable engineering, but they require careful implementation, proper constraints, and realistic expectations. The path forward isn't blind adoption or wholesale rejection, but intelligent integration: combining the generative power of these models with robust control mechanisms, domain-specific fine-tuning, and rigorous quality assurance. Success in enterprise AI doesn't come from chasing hype, it comes from understanding the technology's true capabilities and limitations, then building accordingly.
43 min read
5 min read
15 min read