

8 min read
Artificial intelligence (AI) and particularly NLP applications like GenAI have taken the world by surprise from the end of 2022. They really shook...

5 min read
16/06/2023
Data augmentation is a technique commonly used in machine learning and computer vision to artificially increase the size and diversity of a training data set. It consists of applying several transformations or modifications to existing data samples, generating new samples that retain the same label or class as the original data. Augmented data helps improve model performance by reducing overfitting, improving generalization, and increasing model robustness.
Data augmentation is present in many different domains. To better understand the concept, we will give an example of magnification techniques used on image data. For an image, variations can be applied, such as: rotating by 90º or 45º, shortening or lengthening, saturating the colors, increasing or decreasing the brightness/contrast, changing the lighting, adding noise to the image, and more. If we apply only 4 separate variations to an image, it means that we obtain 4 different images, plus the original, which is 5. We could even have more if the techniques were combined, and even more, if we consider that the order of application of the techniques is relevant. And this only from one image!
If we train a model to identify cats, the model might be able to identify these animals in various positions: close up, from afar, with different colors, in very bright or very dark images, etc. This generalizability is a fundamental goal in the development of computer vision algorithms, and the human ability to detect and recognize objects in different conditions is what is being sought. These variations therefore make the model more robust.
The following figure shows the different transformations that an image can go through.
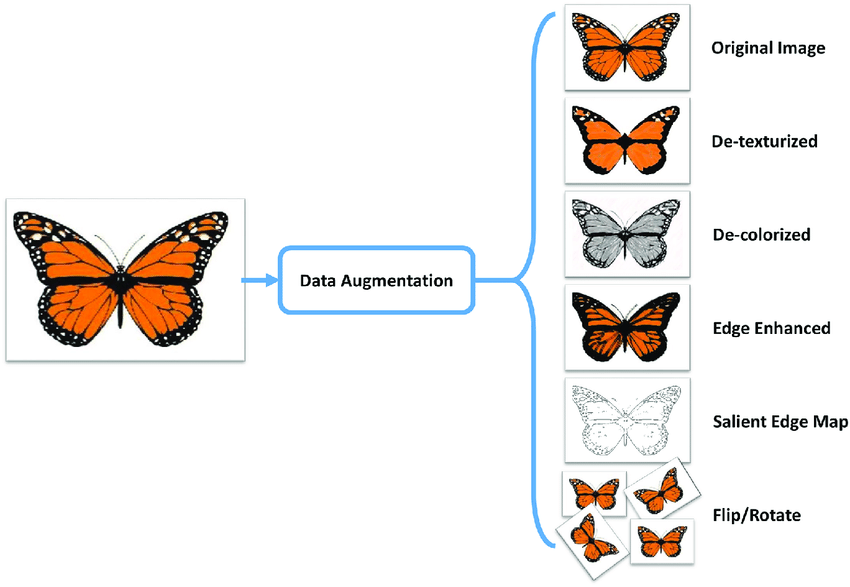
With respect to data augmentation in the text domain, it is a similar process. For example, starting with the text “Show me the nearest restaurant,” we can replace nearest with <distance> and restaurant with <place>. Then, these tags can be replaced with synonyms or antonyms and thus generate other entries. For example: <distance> could be nearest, closest, farthest, etc., and <place> could be restaurant, shop, town, beach, etc. If these entries are combined, the coherence of the sentence should be maintained. Text data augmentation can be used to train models to improve text comprehension and generation, perform machine translation tasks, summarization, and many other applications related to natural language processing.
Read more:
Now that we understand what data augmentation is, we can more simply understand what data augmentation is applied to audio content (called audio data augmentation - ADA).
Just as images are used to train models for detection, audio segments are used to train speech recognition models. ADA is a technique used in audio signal processing to extend and diversify the training data set. It consists of applying controlled transformations and modifications to existing audio samples, with the aim of creating new data instances that retain the essential characteristics of the original audio, but with variations or perturbations.
Related content:
Some of the common techniques used in audio data augmentation are as follows:
Time Stretching: you can increase or decrease the speed of audio playback without changing its pitch or duration. This allows you to simulate variations in the rhythm or speed of speech.
Pitch Shifting: the pitch or frequency of the audio is altered while maintaining its duration. This technique can simulate variations of the voice or musical notes.
Noise Addition: random noise is added to the audio signal. This can help the model to be more robust against environmental noise or variations in recording conditions.
Amplitude Scaling: this adjusts the volume or intensity of the audio signal. It can simulate different sound levels or distances between the audio source and the microphone.
Reverberation: effects are applied to the audio clip to simulate different acoustic environments. This can help the model to better generalize across different recording settings.
Time and Frequency Masking: a random section of the audio is temporarily masked in the time or frequency domain. This technique can simulate missing or damaged audio segments.
.png?width=438&height=438&name=ADA%20(1).png)
These techniques help the model improve its generalizability when dealing with real-world audio data. For example, by adding white noise, we can simulate common sounds like those generated by a fan or air conditioning. By incorporating typical background noises, such as those found at an airport, a construction site, or vehicle traffic on a street, we are replicating sounds that occur in real-life situations.
A practical example of this is when we give instructions to a smartphone while walking down the street and it understands despite the background noise. In this same context, we could also apply a technique to distort the voice which would represent being very close to the microphone (of a smartphone for example) and the audio is somewhat saturated.
By training the model with these realistic conditions, we improve its ability to properly understand and process audio in similar contexts, resulting in a more accurate and effective experience in real-world situations.
Recommended reading:
The Creation of Custom Data Sets to Meet Customer Needs: A BSC Project
Collecting enough audio data can be a big challenge when it comes to building and improving models. Collecting a large data set with varied speech samples can be costly and would require an enormous amount of human effort. ADA techniques can help to resolve the lack of data. By increasing the existing data set, we can generate a wider and more diverse set of audio samples, which can improve the performance of the models.
ADA can also help reduce the cost and time expenditure of data collection, making it a more feasible approach. In addition, augmenting the data can introduce diversity into the data set, which can lead to better generalization of the model and greater accuracy.
.png?width=1920&height=720&name=eBook_EN_CTA2%20(2).png)
While audio data augmentation can be beneficial for improving the performance of machine learning models, some precautions must be taken. One of the biggest problems is the audio quality. By applying augmentation techniques, there is a risk of degrading the audio quality and this, of course, could affect the performance of the model training. Additionally, the application of uncontrolled techniques can produce excessive transformations that can become unrealistic, causing models to learn incorrect and incoherent patterns.
And finally, as in other areas of data processing, augmentation can introduce bias into the resulting data set. Bias can arise due to transformations applied during data augmentation, which can affect the distribution and characteristics of audio samples.
For example, if background airport noise is introduced into all audio samples during data augmentation, the model could learn to associate that specific noise with speech and rely on it to correctly recognize words. This could generate a bias in the model, as it would become dependent on the presence of airport noise to make decisions, and would not be able to recognize speech in other situations where that noise is not present.
You may be interested in:
Beyond these core techniques, there is a growing demand for specialized noise datasets that replicate the acoustic environments where AI systems will operate. Training with curated background noise—whether from busy offices, industrial settings, transportation hubs, or even natural outdoor soundscapes—helps models adapt to real-world variability. At Pangeanic, we have created dedicated noise datasets for artificial intelligence training, designed to extend audio augmentation beyond synthetic manipulations and provide the authentic conditions that speech and sound recognition technologies need to succeed.
At Pangeanic, we have developed a solid expertise in audio data augmentation. Recently, we had the privilege of being awarded a project by European Language Equality, an organization that promotes language equality in Europe. In this project, we proposed techniques to increase audio corpora in four official languages spoken in Spain.
See results: https://european-language-equality.eu/wp-content/uploads/2023/04/ELE2_Project_Report_SpeechCorpus.pdf
We are proud to have contributed significant research to the field of audio data augmentation and to have a team specializing in voice data. We are ready to help your company boost the quality and performance of your voice and audio applications.
At Pangeanic, we go beyond synthetic transformations by providing specialized noise datasets that replicate real-life environments—from offices and transport hubs to outdoor and industrial settings. These resources make your AI models more resilient, accurate, and production-ready. Discover how our noise datasets for artificial intelligence training can help you build smarter, more reliable solutions.

8 min read
5 min read
8 min read