
MOVILIDAD · IA · ESPACIOS DE DATOS Pangeanic, la Universitat Jaume I y ValgrAI culminan un proyecto que conecta datos multilingües, ontologías y...

5 minutos de lectura
16/06/2023
La aumentación de datos es una técnica comúnmente utilizada en el aprendizaje automático y la visión por computadora para aumentar artificialmente el tamaño y la diversidad de un conjunto de datos de entrenamiento. Consiste en aplicar varias transformaciones o modificaciones a las muestras de datos existentes, generando nuevas muestras que conservan la misma etiqueta o clase que los datos originales. Los datos aumentados ayudan a mejorar el rendimiento del modelo al reducir el sobreajuste, mejorar la generalización y aumentar la robustez del modelo.
La aumentación de datos está presente en varios dominios. Para entender mejor el concepto, daremos un ejemplo de técnicas de aumentación en el dominio de las imágenes. Para una imagen, se pueden aplicar variaciones, por ejemplo: rotar en 90º o 45°, se podría achicar o alargar, saturar los colores, aumentar o disminuir el brillo/contraste, cambiar la iluminación, agregar ruido a la imagen, entre otros. Si aplicamos sólo 4 variaciones por separado para una imagen, significa que podemos tener 4 imágenes diferentes, más la original, es decir, 5. Incluso podríamos tener más si se combinan las técnicas, y aún más, si consideramos que el orden es relevante en la aplicación de la técnica, ¡y esto sólo a partir de una imagen!
De esta manera, si entrenamos un modelo para identificar gatos, el modelo podría ser capaz de identificar estos animales en diversas posiciones; de cerca, de lejos, con diferentes colores, en imágenes muy iluminadas o muy oscuras, etc. Esta capacidad de generalización es un objetivo fundamental en el desarrollo de algoritmos de visión por computadora, y se busca que los modelos puedan aproximarse a la habilidad humana de detectar y reconocer objetos en diferentes condiciones. Por lo tanto, estas variaciones hacen que el modelo sea más robusto.
En la siguiente figura, se muestran algunas de las variaciones que podría sufrir una imagen al aplicar técnicas de aumentación.
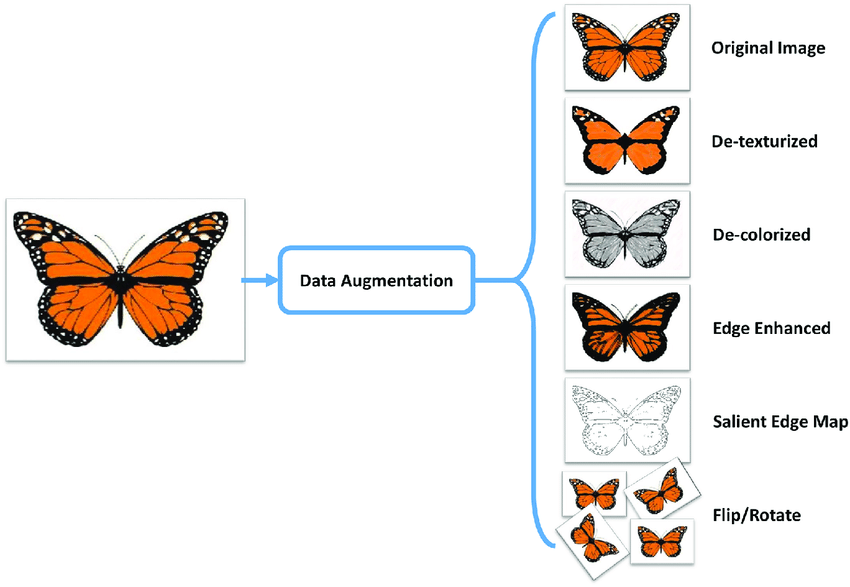
Respecto a la aumentación de datos en el dominio de texto, ocurre algo similar. Por ejemplo, dado un texto “Show me the nearest restaurant”, podemos reemplazar nearest por <distance> y restaurante por <place>. Luego, se pueden reemplazar estos tags por otros sinónimos o antónimos y así generar otras entradas. Por ejemplo: <distance> podría ser nearest, near, close, closer, further away, etc., y <place> lugares como Madrid, Valencia, my town, the beach, my work, etc. Si se combinan estas entradas, se debería mantener la coherencia de la frase.
Hacer aumentación de datos en texto puede servir para entrenar modelos que permitan mejorar la comprensión y generación de texto, realizar tareas de traducción automática, resumen automático, y muchas otras aplicaciones relacionadas con el procesamiento del lenguaje natural.
Siga leyendo:
Aumento de datos para audio: en qué consiste y aplicaciones
Ahora que ya entendemos lo que es la aumentación de datos, podemos entender de manera más simple lo que es la aumentación de datos aplicado a contextos de audios hablados (llamado audio data augmentation -ADA-).
Al igual que las imágenes sirven para entrenar modelos para detección, los segmentos de audio hablados sirven para entrenar modelos de reconocimiento de voz (speech recognition). La aumentación de datos en audios es una técnica utilizada en el procesamiento de señales de audio para ampliar y diversificar el conjunto de datos de entrenamiento. Consiste en aplicar transformaciones y modificaciones controladas a las muestras de audio existentes, con el objetivo de crear nuevas instancias de datos que conserven las características esenciales del audio original, pero con variaciones o perturbaciones.
Contenido relacionado:
La relación entre la ciencia de datos y el aprendizaje automático
Tipos de técnicas para el aumento de datos para audio
Algunas de las técnicas comunes utilizadas en la aumentación de datos en audio son las siguientes:
-
Cambio de velocidad (Time Stretching): Se puede aumentar o disminuir la velocidad de reproducción del audio sin cambiar su tono o duración. Esto permite simular variaciones en el ritmo o la velocidad del habla.
-
Cambio de tono (Pitch Shifting): Se altera el tono o la frecuencia del audio mientras se mantiene su duración. Esta técnica puede simular variaciones en la voz o en las notas musicales.
-
Adición de ruido (Noise Addition): Se agrega ruido aleatorio a la señal de audio. Esto puede ayudar al modelo a ser más robusto frente a ruidos ambientales o variaciones en las condiciones de grabación.
-
Escalado de amplitud (Amplitude Scaling): Se ajusta el volumen o la intensidad de la señal de audio. Esta aumentación puede simular diferentes niveles de sonido o distancias entre la fuente de audio y el micrófono.
-
Reverberación (Reverberation): Se aplican efectos de reverberación al clip de audio para simular diferentes entornos acústicos. Esto puede ayudar al modelo a generalizar mejor en diferentes configuraciones de grabación.
-
Enmascaramiento de tiempo y frecuencia (Time and Frequency Masking): Se enmascara temporalmente una sección aleatoria del audio en el dominio del tiempo o de la frecuencia. Esta técnica puede simular segmentos de audio faltantes o dañados.
.png?width=501&height=501&name=ADA%20(3).png)
Estas técnicas ayudan al modelo a mejorar su capacidad de generalización al enfrentarse a datos de audio del mundo real. Por ejemplo, al agregar ruido blanco (noise addition), podemos simular sonidos comunes como los generados por un ventilador o un aire acondicionado. Al incorporar ruidos de fondo típicos, como los que se encuentran en un aeropuerto, una construcción o el tráfico de vehículos en una calle, estamos replicando sonidos que ocurren en situaciones de la vida real.
Un ejemplo práctico de esto es cuando le damos instrucciones al móvil mientras caminamos por la calle y este nos entiende transcribiendo o ejecutando alguna operación). En este mismo contexto, también podríamos aplicar una técnica para distorsionar la voz lo que representaría que alguien esté muy cerca del micrófono (de un móvil por ejemplo) y se escuche un tanto saturado el audio.
Al entrenar el modelo con estas condiciones realistas, mejoramos su capacidad para comprender y procesar adecuadamente los audios en contextos similares, lo que resulta en una experiencia más precisa y efectiva en situaciones del mundo real.
Lectura recomendada:
Beneficios del aumento de datos para audio
Disponer de datos de audio suficientes puede suponer un gran reto a la hora de construir y mejorar los modelos. Recopilar un gran conjunto de datos con muestras de habla variadas puede ser costoso y llevaría a un esfuerzo humano no menor. Las técnicas ADA pueden ayudar a resolver la falta de datos. Al aumentar el conjunto de datos existente, podemos generar un conjunto más amplio y diverso de muestras de audio, lo que puede mejorar el rendimiento de los modelos.
ADA también puede ayudar a reducir los costes económicos y de tiempo de la recopilación de datos, lo que lo convierte en un enfoque más factible. Además, el hecho de aumentar los datos puede introducir diversidad en el conjunto de datos, lo que puede conducir a una mejor generalización del modelo y a una mayor precisión.

Consideraciones del aumento de datos para audio
Si bien la aumentación de datos de audio puede ser beneficiosa para mejorar el rendimiento de los modelos de aprendizaje automático, se deben tener ciertas precauciones. Uno de los mayores problemas es la calidad del audio. Al aplicar técnicas de aumentación, existe el riesgo de degradar la calidad del audio y esto, desde luego, podría afectar en el rendimiento en un modelo en un entrenamiento. Por otro lado, la aplicación de técnicas sin control, pueden producir transformaciones excesivas que pueden llegar a ser poco realistas, haciendo que los modelos aprendan patrones incorrectos e incoherentes.
Y finalmente, al igual que en otras áreas de procesamiento de datos, la aumentación puede introducir sesgos (bias) en el conjunto de datos resultante. El bias puede surgir debido a las transformaciones aplicadas durante la aumentación de datos, que pueden afectar la distribución y las características de las muestras de audio.
Por ejemplo, si durante la aumentación de datos se introduce ruido de aeropuerto de fondo en todas las muestras de audio, el modelo podría aprender a asociar ese ruido específico con el habla y depender de él para reconocer correctamente las palabras. Esto podría generar un sesgo en el modelo, ya que se volvería dependiente de la presencia del ruido de aeropuerto para tomar decisiones, y no sería capaz de reconocer el habla en otras situaciones donde no haya ese ruido presente.
Le puede interesar:
Pangeanic, expertos en técnicas para el aumento de datos para audio
En Pangeanic, hemos desarrollado una sólida experiencia en la aumentación de datos de audio. Recientemente, tuvimos el privilegio de adjudicarnos un proyecto de European Language Equality, una organización que promueve la igualdad lingüística en Europa. En este proyecto, propusimos técnicas para aumentar corpus de audio en cuatro idiomas hablados en España.
El trabajo: https://european-language-equality.eu/wp-content/uploads/2023/04/ELE2_Project_Report_SpeechCorpus.pdf
Nos enorgullece haber contribuido significativamente al campo de la aumentación de datos de audio y contar con un equipo especializado en voz. Estamos listos para ayudar a su empresa a impulsar la calidad y el rendimiento de sus aplicaciones de voz y audio.