

8 min read
We live in the age of data-driven decision-making. Data has become the new oil, and personal data is one of the most refined fuels. As a result,...
-4.png)
4 min read
27/10/2022
k-anonymity is a concept linked to privacy and information security, involving "hiding" values within a multitude of data.
It arose in response to the scientific quest to guarantee impossible re-identification of individuals through processed data, while ensuring that the information remains useful for the purpose of analysis.
If you want to know more about the importance of k-anonymity to preserve the privacy of personal data, read on this article
k-anonymity is a technique that has evolved over the years. These days, it is an effective way to protect personal and sensitive data in order to comply with the GDPR.

k-anonymity is the attribute of the anonymized data that quantitatively defines the level of anonymity of the subjects within a data set that has undergone de-identification.
Consequently, the k-anonymity measures the likelihood of anonymized data being used by third parties to extract sensitive or personal information.
In order to delve deeper into this concept, here is a little reminder of the different types of data:
Direct identifiers (passport numbers, names, etc.)
Indirect identifiers (can identify the individual when grouped with other data)
Sensitive data, which represent intimate characteristics of the individual (diseases, income, etc.)
In this context, k-anonymity is mainly intended for hiding indirect identifier data (quasi-identifier attributes).
Within a data set, an individual will only be k-anonymous if, given any combination of indirect identifiers, there are at least a k-1 number of individuals that also share the same identifying data.
Therefore, to guarantee a low probability of re-identification, it is necessary for k-anonymity algorithms to work with a minimum value k.
As can be seen, both identifying data (direct and indirect) and sensitive data pertaining to the same person can coexist within a data set.
If malicious third parties or hackers/cybercriminals connect these types of data, they will be able to track the information until they connect it to the data subject, i.e. until they re-identify the individual.
k-anonymization helps prevent privacy breaches by ensuring that it is impossible to connect or link those data categories; it ensures that the re-identification process cannot be carried out.
%20(1).png?width=1200&height=627&name=Pangeanic%20-%20Blog%20(42)%20(1).png)
Related content: 6 Personal Data Anonymization Techniques You Should Know About
To keep data anonymous, the following k-anonymity methods are used on data sets:
Generalization. This k-anonymity method transforms indirect identifiers, replacing specific values with more general ones. This increases the amount of data with the same values, but establishes ranges or hierarchies.
Generalization minimizes the specificity of an identifier, while maintaining the accuracy of the values.
Global or local generalization can be applied. The latter offers greater precision in the values, but complicates the way the results are presented.
For example, if the value to generalize is ⟨age = 42⟩, it can simply be replaced by a range comprising the value 42. The range could be ⟨40 to 49⟩.
Suppression. The second method for k-anonymization is based on the complete elimination of the identifier value within the data set. This technique should only be applied for a data type or range that does not affect the purpose of the information.
Part of the value is usually removed and replaced with asterisks.
Following the example given for generalization, if age is irrelevant for the purpose of information collection, using this method, the age range data can be removed, changing ⟨age = 42⟩ to ⟨age = **⟩.
A k-anonymity algorithm can apply suppression or generalization separately, or it can combine both methods
Database without k-anonymity
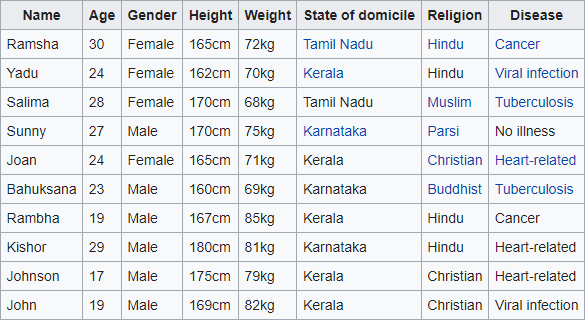
Source: Wikipedia
Database with k-anonymity
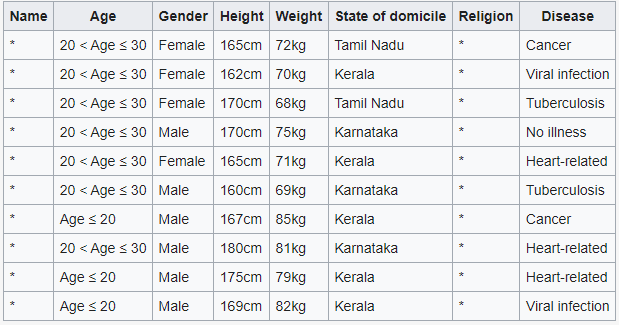
Source: Wikipedia
As there are at least two distinct lines for every combination of the attributes "Engagement," "Gender," and "Residence State" present in each given column of the table, these data are both anonymous with regard to these characteristics.
Every quasi-identifiable tuple appears in at least k records for a set of data with k-anonymity.
Dynamic data masking hides or modifies values at the time the information is consulted. The de-identification process can preserve the format of the data without the need to perform manual tasks such as deleting or copying values.
Therefore, dynamic data masking streamlines the analysis process, preserves the usefulness of the values, and eliminates the risk of human error. This facilitates dynamic anonymization that allows companies or organizations to:
Address problems associated with protecting data in the cloud
Process identifiable and sensitive data in a secure manner
In k-anonymity, both the generalization and suppression techniques involve certain types of distortion:
k-anonymization based on suppression usually involves the removal of a considerable number of values from a data set. This means a bias compared to the original structure of the information and, as a consequence, could distort the results.
k-anonymization based on generalization implies losing the ability to draw conclusions from atomized data and to relate them to other values.
These distortions represent significant limitations when there are few inputs. However, in the case of data sets with large numbers of input records, k-anonymity distortions do not imply a high distortion of the analysis results.
At Pangeanic, we specialize in multilingual anonymization. We have developed an anonymization service based on artificial intelligence, specifically on machine learning.
Our data anonymization processes are not limited to removing direct identifiers, but also remove secondary information, as well as any traces or electronic trails that may lead to the identification of the data subject.
Anonymization is becoming an essential practice for any company or organization that bases its work on data collection and processing. We understand the importance of this process, which is why our anonymization software enables compliance with the EU's GDPR and other regulations, such as California's CCPA.
Masker, Pangeanic's Anonymization tool, uses AI to automatically identify personal data and replace sensitive information using different Anonymization techniques. In addition, it is multilingual.
Do you know its pricing? On our page you have more information.
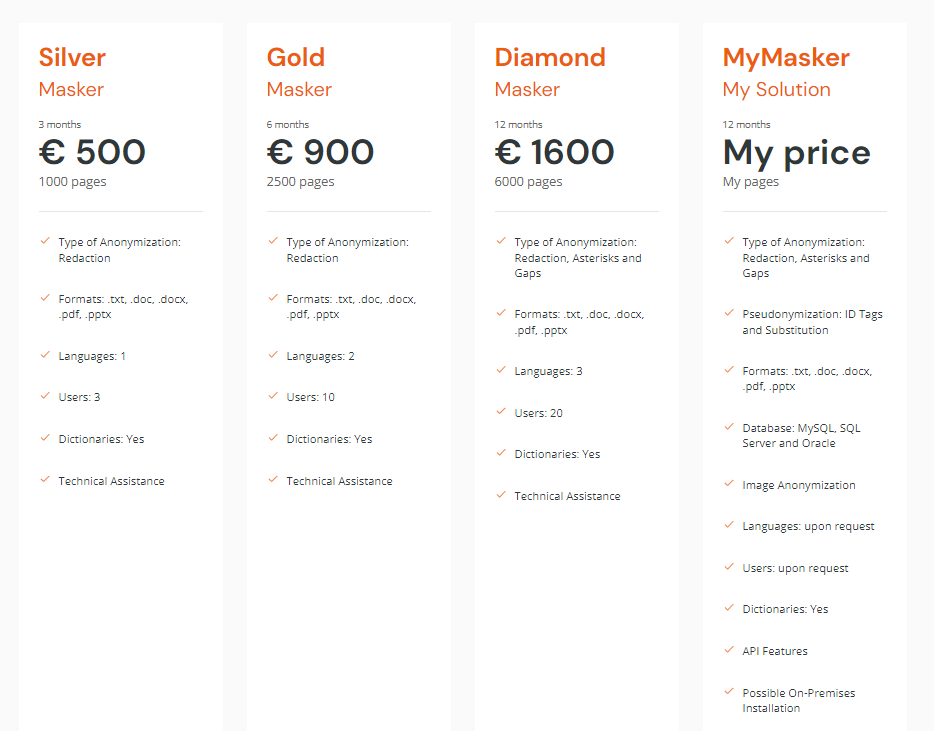
At Pangeanic, we help you avoid penalties, effectively protect data privacy, and maintain your company's corporate reputation.
Contact us. We will provide you with a customized solution.

8 min read
7 min read