La anonimización de base de datos es un mecanismo que garantiza la confidencialidad de la información de los individuos, a través de técnicas en las...
-4.png)
4 minutos de lectura
27/10/2022
El k-anonimato es un concepto ligado a la privacidad y seguridad de la información e implica “esconder” valores en una gran multitud de datos.
Surge como respuesta ante la búsqueda científica de garantizar la no reidentificación de los individuos a través de los datos tratados, pero asegurando al mismo tiempo que la información siguiera siendo útil para el objeto del análisis.
Si quiere saber más sobre la importancia de el k-anonimato para preservar la privacidad de los datos personales, siga leyendo este artículo.
El k-anonimato es una técnica que ha evolucionado, siendo hoy en día una manera efectiva para la protección de datos personales y sensibles para cumplir con el RGPD.

¿Qué es el k-anonimato?
El k-anonimato es el atributo de los datos anonimizados que define, cuantitativamente, el nivel de anonimato de los individuos dentro de un grupo de datos que han sido sometidos a la desidentificación.
En consecuencia, el k-anonimato es una medida de la probabilidad de que los datos anonimizados puedan servir a terceros para extraer información sensible o personal.
Para profundizar sobre este concepto, es preciso recordar que los tipos de datos son:
-
Los identificadores directos (número de pasaporte, nombre, etc.),
-
Los identificadores indirectos (pueden identificar al individuo al agruparlos con otros datos),
-
Los sensibles, que representan características íntimas del individuo (enfermedades, ingresos, etc.).
En este contexto, el k-anonimato tiene como objetivo principal trabajar o esconder los datos identificadores indirectos (atributos cuasi-identificadores)
Y dentro de un conjunto de datos, un individuo solo será k-anónimo si, ante cualquier combinación que se realice de los identificadores indirectos, exista por lo menos una cantidad de K-1 individuos que también comparten los mismos datos identificadores.
Por lo tanto, para garantizar una baja probabilidad de reidentificación, es necesario que los algoritmos de k-anonimato trabajen con un valor mínimo k.
¿Cómo ayuda el k-anonimato a prevenir fugas de privacidad?
Como se observa, dentro de un conjunto de datos pueden coexistir tanto datos identificadores (directos e indirectos) como datos sensibles de una misma persona.
Si terceros malintencionados o hackers/ciberdelincuentes conectan estos tipos de datos, podrán hacer un rastreo de la información hasta que la conecten con la persona titular, es decir, hasta que reidentifiquen al individuo.
La k-anonimización ayuda a prevenir fugas de privacidad al garantizar que sea imposible conectar o relacionar esas categorías de datos; por lo tanto, asegura que no pueda llevarse a cabo el proceso de reidentificación.
%20(1).png?width=1200&height=627&name=Pangeanic%20-%20Blog%20(42)%20(1).png)
Métodos para la k-anonimización
Para mantener los datos anónimos, existen los siguientes métodos de k-anonimato para un conjunto de datos:
-
La generalización. En este método de k-anonimato, los identificadores indirectos se transforman, sustituyendo los valores específicos por otros más generales. Así se incrementa la cantidad de datos con los mismos valores, pero estableciendo rangos o jerarquías.
-
La generalización minimiza la especificidad de un dato identificador, permitiendo al mismo tiempo mantener la precisión en los valores.
-
Puede aplicarse una generalización global o local. Esta última ofrece mayor precisión en los valores, pero complica la manera de presentar los resultados.
-
Por ejemplo: si el valor a generalizar es ⟨edad = 42⟩, simplemente se sustituye dicho valor por un rango que comprenda el valor 42. Puede ser un rango de ⟨40 a 49 años⟩.
-
La supresión. El segundo método para la k-anonimización se basa en la eliminación completa del valor identificador dentro del grupo de datos. Esta técnica solo debe aplicarse para un tipo de dato o rango de datos que no sean importantes para el fin de la información.
-
Normalmente se elimina parte del valor y se reemplaza con asteriscos.
-
Por ejemplo: siguiendo el ejemplo expuesto en la generalización, si la edad es irrelevante para el objetivo de la recopilación de información, con este método de k-anonimato pueden eliminarse los datos de los rangos de edad, de forma que pasaríamos de ⟨edad = 42⟩ a ⟨edad = **⟩.
Un algoritmo de k-anonimato puede aplicar por separado la supresión o la generalización o puede combinar ambos métodos.
Ejemplo de k-anonimato aplicado a bases de datos
Este es un ejemplo de k-anonimato aplicado a base de datos para el sector sanitario.
Base de datos sin k-anonimato:
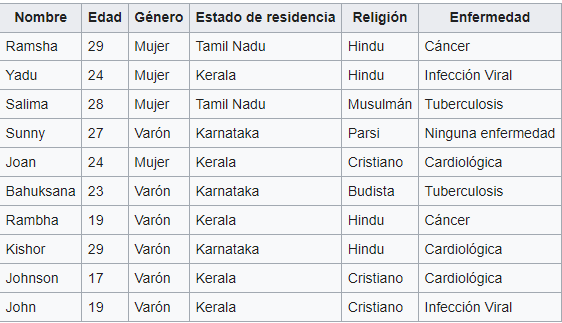
Fuente: Wikipedia
Ejemplo de base de datos k-anonimato:
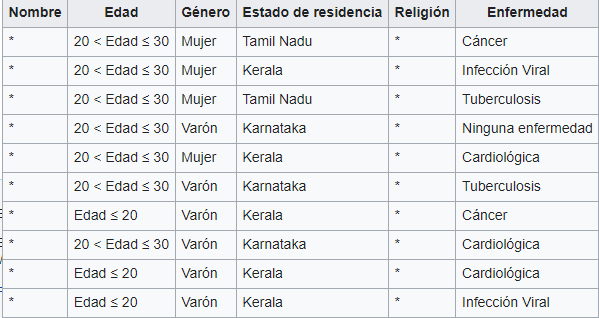
Fuente Wikipedia
Como hay al menos dos filas idénticas para cada combinación de los atributos "Edad", "Género" y "Estado de residencia" presentes en cualquier columna dada de la tabla, estos datos son dos anónimos con respecto a estas características.
Cada tupla cuasi identificadora se presenta en al menos k registros para un conjunto de datos con k-anonimato.
Para un conjunto de datos con k-anonimato, cada tabla de cuasiidentificador se representa en al menos k registros.
La relación entre el enmascaramiento dinámico de datos, la desidentificación y la k-anonimización
El enmascaramiento dinámico de datos oculta o modifica valores en el momento en que se efectúa la consulta de la información. De esta forma es posible que en el proceso de desidentificación se conserve el formato de los datos sin la necesidad de ejecutar tareas de manera manual como la eliminación o copia de valores.
Por lo tanto, el enmascaramiento dinámico de datos agiliza el proceso de análisis, permite conservar la utilidad de los valores y elimina el riesgo de error humano. Esto facilita que se lleve a cabo una anonimización dinámica que permita a las empresas u organizaciones:
-
Afrontar los problemas asociados a la protección de datos en la nube, y
-
Tratar datos identificadores y sensibles de manera segura.
.png?width=1200&height=627&name=servicios%20de%20traduccion%20(1).png)
Limitaciones del k-anonimato
En el k anonimato, tanto la técnica de generalización como la de supresión implican ciertos tipos de distorsión:
-
La k-anonimización basada en la supresión, normalmente, implica la eliminación de una cantidad considerable de valores de un grupo de datos. Esto significa un sesgo para la estructura original de la información y, como consecuencia, podría distorsionar los resultados.
-
La k-anonimización fundamentada en la generalización supone la pérdida de la capacidad para sacar conclusiones a partir de los datos atomizados y de relacionarlos con otros valores.
Estas distorsiones representan una enorme limitación cuando se tienen pocas entradas. Pero en el caso de grupos de datos con gran cantidad de registros de entrada, las distorsiones del k-anonimato no implican una alta afectación de los resultados del análisis.
Pangeanic y la anonimización
En Pangeanic nos especializamos en la anonimización multilingüe. Hemos desarrollado un servicio de anonimización basado en la inteligencia artificial, concretamente en el machine learning (aprendizaje automático).
Nuestros procesos para anonimizar datos no se limitan a suprimir identificadores directos, sino que también eliminan la información secundaria y todo rastro o pista electrónica que puedan conducir a la identificación de la persona titular.
La anonimización está siendo una práctica esencial para toda empresa u organización que base su trabajo en la recogida y tratamiento de datos. Entendemos la gran importancia que cobra este proceso, por lo que nuestro software de anonimización permite cumplir con el RGPD de la Unión Europea y con las demás normativas, como la CCPA de EE. UU.
Amplía información: Cómo tratar los datos anonimizados según el RGPD
Masker, (la herramienta de Anonimización de Pangeanic) utiliza la IA para identificar automáticamente la información personal y sustituir la información sensible por diferentes tipos de Anonimización. Además, es multiidioma.
En Pangeanic le ayudamos a evitar sanciones, a proteger efectivamente la privacidad de los datos y a mantener la reputación corporativa de su empresa.
Póngase en contacto con nosotros.
