

12 min read
Two technologies are often discussed within the "translation industry" or "localization community": AI translation and Machine Translation. While...
3 min read
12/07/2014
Translation memories are a feature of computer-assisted translation systems and play a big part in making the translation process more efficient. Translation memories allow a translator to re-use any of the text segments that have previously been translated.
A translation memory is basically a small or large database which stores information as the translator works. This information is based on the concept of a source sentence and a target sentence. If a new sentence is being translated and the database finds a similar entry, it then shows the target sentence to the translator as a reference. This obviously helps the translator as they do not need to search for reference material, as well as keeping terminology and regular expressions consistent. It also saves time and money, as previous translations can be recalled and used entirely or partially at a fraction of the cost and time that translating new material from scratch would incur.
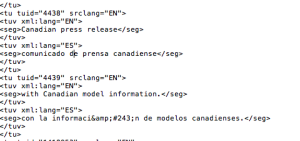
A translation memory (TM) serves as a database for translated segments, which along with their source segments are stored in the memory of computer-assisted translation (CAT) systems as translation units. As we mentioned before, these translation units are retrieved automatically by the computer-assisted translation tool whenever it comes across not only an identical, but also a “similar” fragment of text. This means that if we have a 10-word sentence and 7 of those appear in a new sentence, we have a 70% match, and the translation memory will show us the previously translated sentence.
A CAT tool typically comes with a “fuzzy search“ feature. This feature allows the translator to look for part of a segment in the TM. That “string of words” can be retrieved even when the two full segments are not an exact replica of each other. These “similar sentences” are known as fuzzy matches. The retrieved segments can either be used within the same document or a different one.
Translation units are the elementary translatable units saved in the TM. Text is broken down into smaller phrases or sentences, which are saved as segments. Translation units cannot be further broken down into smaller segments, as the CAT system might not be able to translate them adequately in relation to the contexts in which they are used.
The translation memory assesses segments and measures their relevancy to the current segment in percentages. A segment showing 99% similarity to a stored segment may only differ in terms of a single letter or punctuation. However, fragments whose similarities are less than 65% are not as useful, and it is advisable to translate manually in such cases.
The document being translated may also contain the same segment repeated several times. The computer-assisted translation tool analyzes a document before translation and identifies such identical segments. As soon as the first identical segment is translated, the fragment is saved in the translation memory. This saved segment of text, which shows 100% similarity with other identical segments, is automatically propagated to save time and effort during the translation process. These identical, repeated segments are called repetitions in the language of CAT systems.
TMs allow the translator to translate the given material in an effective and efficient manner. This way, time-effective translation is ensured and consistency is maintained throughout projects. Furthermore, it is also cost-effective. The adequate use of repetitions, 100% matches and fuzzy matches plays a fundamental role in ensuring efficient translation processes. The automatic re-use of similar terms by the CAT tool, retrieved from the TM, allows the translator to not only keep up with time constraints, but also maintain terminology consistency.
Effective use of translation memories also ensures quality control. A CAT system automatically suggests the re-use of similar terms, where applicable, adding consistency and flow to the translated document. This makes the translated document more authentic.

CAT tools and TMs are useful inventions in the field of translation. Not only are they devoid of the typical shortcomings of machine translation technology, but also add to the immediacy of the process of quality translation. There are several CAT tools that use translation memories as the basis of their technology. Some tools are free, like OmegaT. Others come at higher prices, like the feature-packed Trados (now Studio). Smart desktop versions like MemoQ are constantly increasing their market share. Deja Vu is a very good Spanish tool which has received less limelight than it deserves, and provides excellent value for money. Transit is also a classic tool, even if a little outdated. Wordfast is very popular among freelance translators and some translation agencies. Heartsome became open-source after closing down operations in 2014. Cloud-based tools like MemSource and XTM are becoming increasingly popular, thanks to their SaaS models.
Read more: Translation Memories
12 min read
3 min read
4 min read