

6 min read
Pangeanic develops SAVIA: An AI-Powered Virtual Assistant Platform with funding from IVACE
3 min read
12/06/2025
In the field of private Generative Artificial Intelligence (GenAI), a crucial component is transforming how virtual assistants access and utilize real-world knowledge: RAG, or Retrieval-Augmented Generation.
RAG is an innovative architecture that combines the power of cutting-edge language models with the ability to retrieve information from external knowledge bases. This synergistic combination enables virtual assistants to provide more informed, accurate, and up-to-date responses, surpassing the limitations of traditional approaches that rely solely on knowledge acquired during training. It is worth recalling that one of the significant limitations of early large language models (LLMs) with conversational capabilities, such as ChatGPT-3.5, was their restricted knowledge cut-off date. These models were unaware of events beyond October or November of 2021 or 2022. Over time, internet search functionalities have been integrated into these systems, enabling them to summarise information from the top three to five search results. However, this approach can still overlook critical details and remains susceptible to hallucinations, as the most relevant data is not always found on the first page of search results.
Consider any company, business, or organization—regardless of size. All of them generate and have access to large volumes of data accumulated over time. This data does not always stem directly from operations: ISO standards, internal procedures, regulations, contracts, applicable legislation that must remain up to date, competitor intelligence, industry reports… The marketing department holds one set of documents, finance another, and human resources yet another. Soon, the search for information becomes chaotic, resulting in significant inefficiencies.
A large portion of this data consists of unstructured text and images. Traditional approaches to analyzing unstructured data and generating content from it typically rely on keyword or synonym matching. However, such methods fail to capture the full semantic context of a document—or connections across multiple documents. Once again, we face a knowledge management challenge, with both vertical and horizontal inefficiencies that negatively impact business operations. In certain cases, the consequences are even more severe: a company or organization might be monetizing its content and intellectual assets through subscriptions, yet still lack the means to surface relevant information for internal or external stakeholders.
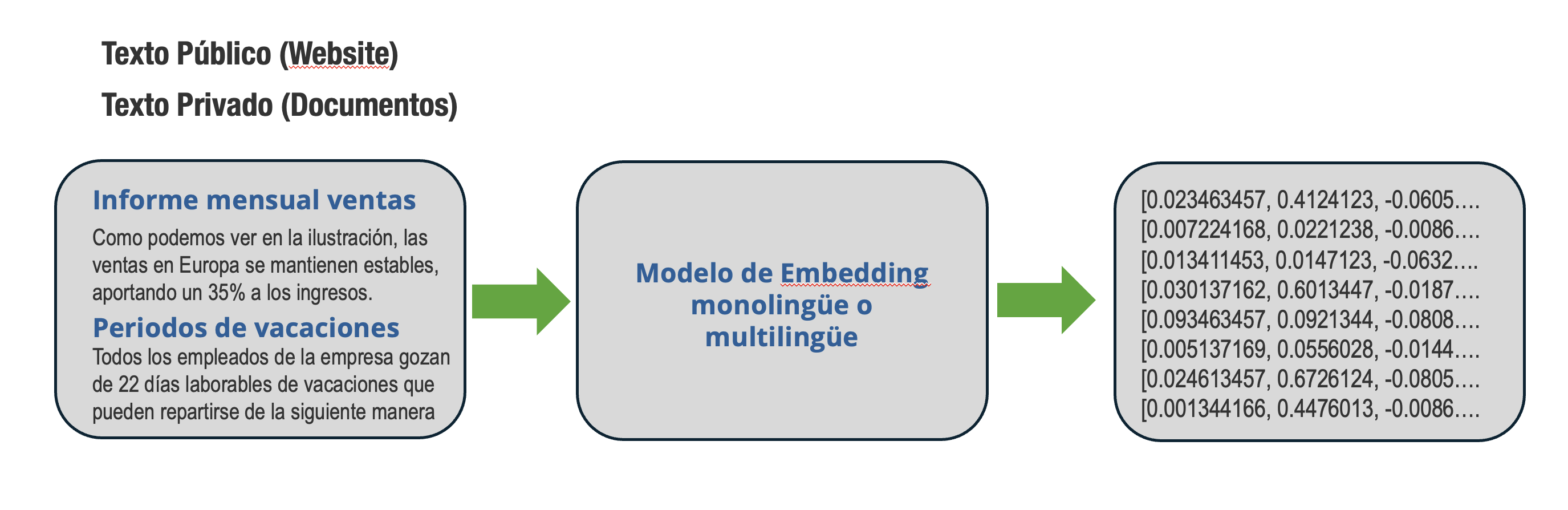
The transformation of text into word embeddings—what Microsoft refers to as “Instructions”—leverages machine learning (ML) capabilities to extract the essence of unstructured data. These embeddings are generated by language models that map natural language text into numerical representations, encoding contextual information along the way. This conversion is a foundational step in many natural language processing (NLP) applications powered by LLMs, including Retrieval-Augmented Generation (RAG), text generation, entity extraction, and a range of other downstream business processes.
 Text-to-Embedding Conversion Using Monolingual or Multilingual Models
Text-to-Embedding Conversion Using Monolingual or Multilingual Models
At the core of a RAG system lies a retrieval model capable of efficiently searching large knowledge bases—such as Wikipedia or specialized databases. This model uses information retrieval techniques to identify the most relevant text segments in response to a given query. These segments are then passed to a generative language model, which processes them and generates a coherent, contextualized response.
One of RAG’s most powerful features is its ability to combine knowledge learned during training with information retrieved from external sources. This allows virtual assistants to respond more accurately to queries that require up-to-date insights or domain-specific information.
For instance, if a user inquires about a recent event, the RAG retrieval model can search current online sources for the latest details, which the generative model then integrates into a fluent and natural response.
However, a virtual assistant based on RAG is not limited to answering questions. It also has applications in tasks such as summarization, assisted writing, and the transformation of text into structured knowledge. By combining learned and retrieved knowledge, RAG enables the creation of more informed and relevant content across a wide range of use cases.
Still, as with human interpretation, one of the ongoing challenges is ensuring the accuracy and reliability of the knowledge bases being used. Any bias or inaccuracies present in the source data will be reflected in the generated content.
Nevertheless, a RAG-based virtual assistant like ECOChat represents a significant advancement in the field of Generative AI, empowering virtual assistants to deliver more informed and accurate responses. As this technology continues to evolve, we can expect more sophisticated implementations that address current limitations and further expand the capabilities of virtual assistants.
If we are to retain a single key takeaway, let it be this: RAG is an innovative architecture that enables GenAI-powered virtual assistants to access and utilize the knowledge you choose to provide, tailored to your industry, organization, or enterprise, resulting in more accurate and relevant responses. By combining powerful language models with the ability to retrieve external information, RAG is ushering in a new era of more informed, precise, and useful virtual assistants—capable of delivering richer and more valuable user experiences, as demonstrated by our very own ECOChat.
Save thousands of hours by streamlining internal and external information searches, as well as client and staff queries. Your data remains private and accessible across your organization. Hallucinations—common in generic AI systems—are eliminated. Use adaptive GenAI for translation with LLMs and neural networks enhanced by automated post-editing.
6 min read
3 min read
7 min read