

5 min read
If you need to translate a large amount of information or documents in a fast and practical way, Pangeanic's plugins and API are the ideal solution....
2 min read
31/03/2021
 As a result of this,
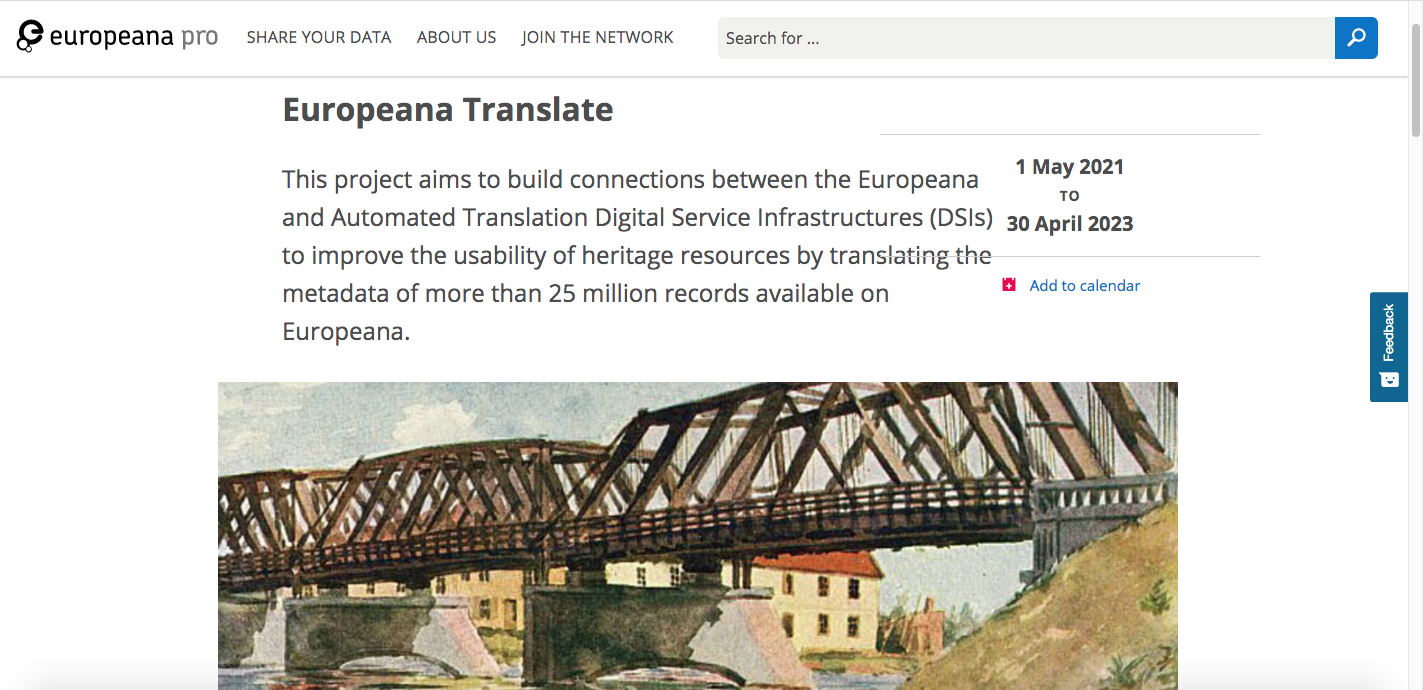
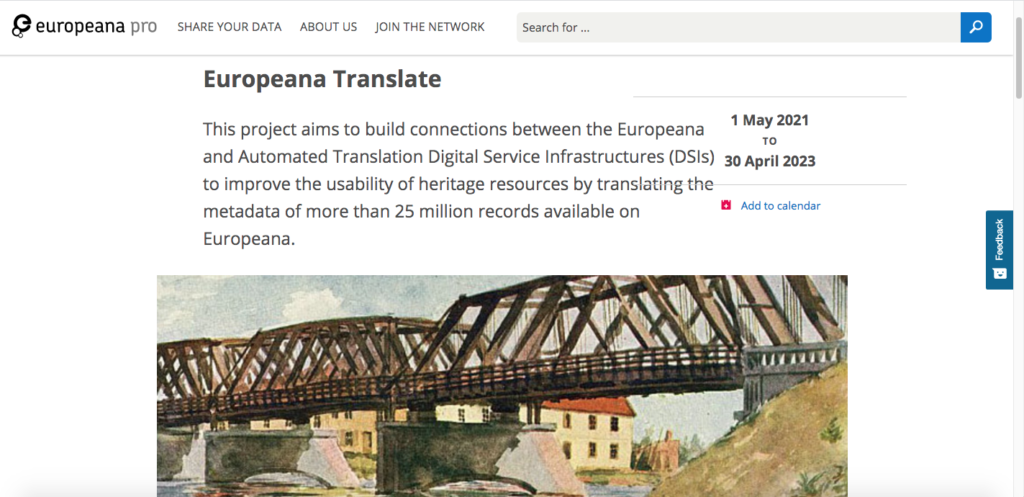
Europeana Translate was born. In order to provide access to all of this cultural heritage and remove the source language barriers, this project aims to connect the digital service infrastructures (DSI) of the platform with those of machine translation. As a result, the project will translate the metadata of these millions of records available on Europeana into English and will send them back to the Europeana core service platform as enrichments.
As a result of this,
Europeana Translate was born. In order to provide access to all of this cultural heritage and remove the source language barriers, this project aims to connect the digital service infrastructures (DSI) of the platform with those of machine translation. As a result, the project will translate the metadata of these millions of records available on Europeana into English and will send them back to the Europeana core service platform as enrichments.
 As a team of language technology professionals, Pangeanic works on a daily basis on the implementation of language processing tools that allow to structure data so that humans or machines can extract actionable insights. These tools allow companies and institutions from all industries (law, finance, culture and tourism, among many others) to improve their services by gaining greater knowledge and saving time and resources when managing their projects.
Deep Adaptive technology for machine translation allows to clone engines that learn from content previously generated by the user, or similar content, and that imitate vocabulary and style. Each learning level produces deep learning algorithms that enable the data to be weighted and allow the engines to become a
fundamental tool for those users that have specialized terminology and/or large-scale language content generation or processing needs. This technology will help Europeana, which is currently in its fourth DSI operational cycle, to
overcome language barriers and be able to offer European citizens and institutions access to its content according to their
multilingual needs. This project falls within the framework of Europe’s commitment to becoming one of the most competitive and dynamic knowledge-based economies. With just one click, it offers the world a cultural background that includes books, paintings, films, audio material, maps and newspapers, as well as other kinds of highly valuable records that soon we will be able to enjoy and understand with no restrictions.
As a team of language technology professionals, Pangeanic works on a daily basis on the implementation of language processing tools that allow to structure data so that humans or machines can extract actionable insights. These tools allow companies and institutions from all industries (law, finance, culture and tourism, among many others) to improve their services by gaining greater knowledge and saving time and resources when managing their projects.
Deep Adaptive technology for machine translation allows to clone engines that learn from content previously generated by the user, or similar content, and that imitate vocabulary and style. Each learning level produces deep learning algorithms that enable the data to be weighted and allow the engines to become a
fundamental tool for those users that have specialized terminology and/or large-scale language content generation or processing needs. This technology will help Europeana, which is currently in its fourth DSI operational cycle, to
overcome language barriers and be able to offer European citizens and institutions access to its content according to their
multilingual needs. This project falls within the framework of Europe’s commitment to becoming one of the most competitive and dynamic knowledge-based economies. With just one click, it offers the world a cultural background that includes books, paintings, films, audio material, maps and newspapers, as well as other kinds of highly valuable records that soon we will be able to enjoy and understand with no restrictions.

5 min read
2 min read