Existe un debate en la sociedad sobre el cerebro que subyace tras la Inteligencia Artificial (IA). El desarrollo de algoritmos y máquinas capaces de ...
-1.png)
4 minutos de lectura
11/07/2023
Vivimos en la era de la toma de decisiones basada en datos. Los datos se han convertido en el nuevo petróleo, y los datos personales son uno de los combustibles más refinados. Como resultado, la inteligencia artificial (IA) se ha convertido en una fuerza transformadora que influye profundamente en todos los sectores, desde la atención médica hasta las finanzas y más allá.
Sin embargo, el poder de la IA conlleva una responsabilidad inherente: garantizar el uso ético de los datos en los que se basa. En el centro de esta obligación ética se encuentra el concepto de anonimización de datos, un aspecto crítico, pero a menudo pasado por alto de la construcción de marcos éticos de IA.
La anonimización de datos se refiere al proceso de proteger los datos identificables para preservar la privacidad del individuo mientras los datos siguen siendo útiles para el análisis. Este proceso de desidentificación es crucial no solo para cumplir con las regulaciones de protección de datos en evolución, sino también para garantizar que el desarrollo y la implementación de los sistemas de IA sean éticos.
Lectura recomendada:
Navegando por la intersección de la privacidad y la utilidad
La sofisticación de los algoritmos de IA en la actualidad significa que se recopila, almacena, procesa y analiza una cantidad de datos sin precedentes. Si bien estos datos son fundamentales para mejorar y adaptar los sistemas de inteligencia artificial, plantean importantes problemas de privacidad. Estas preocupaciones se amplifican cuando los sistemas de inteligencia artificial manejan datos confidenciales, como registros de atención médica, información de identificación personal o transacciones financieras. Es en esta intersección de utilidad y privacidad donde la anonimización de datos se convierte en un pilar fundamental en la construcción de una IA ética.
Las técnicas de anonimización, como la seudonimización, la agregación o el cifrado, no solo protegen la privacidad al reducir el riesgo de exposición de los datos personales, sino que también mantienen la utilidad de los datos para los algoritmos de IA. Garantizan los derechos y libertades de los interesados sin obstaculizar el desarrollo y la implementación de sistemas de IA. Cuantos más datos deban recopilarse y compartirse entre sistemas, mayor será el riesgo de PII en juego.
Los usuarios/consumidores/ciudadanos podemos pensar que no hay nada que podamos hacer al respecto y que la privacidad ya no existe en tiempos de teléfonos inteligentes, geolocalización, redes sociales, etc. Sin embargo, los custodios de nuestros datos no pueden actuar libremente. Hay y debe haber regulaciones que limiten los usos de datos personales en el entrenamiento de IA o que exijan directamente su eliminación, básicamente porque no sabemos dónde pueden terminar nuestros datos personales y quién puede consultarlos.
La Perspectiva Legal: Normativa de Protección de Datos
Desde un punto de vista legal, no se puede exagerar la importancia de la anonimización de los datos. Las leyes de protección de datos, como el Reglamento General de Protección de Datos (GDPR) en la Unión Europea o la Ley de Privacidad del Consumidor de California (CCPA) en los Estados Unidos, imponen reglas estrictas sobre cómo se pueden procesar los datos personales, y el incumplimiento puede conducir a multas y sanciones significativas.
Según estas leyes, los datos anonimizados no se consideran datos personales. Por lo tanto, si la anonimización de datos se ejecuta correctamente, las empresas pueden eludir las complejidades de estas regulaciones y evitar las graves consecuencias del incumplimiento.
Es crucial comprender que los estándares de lo que constituye una anonimización efectiva son altos, especialmente dadas las capacidades de los algoritmos de aprendizaje automático modernos para volver a identificar potencialmente los datos anonimizados. Por lo tanto, el gobierno y las empresas deben mantenerse al tanto de los avances tecnológicos y los desarrollos legales para garantizar que sus técnicas de anonimización cumplan con la ley y sean éticamente responsables.
Confianza en la IA: el papel de la anonimización de datos
La confianza es la base de la adopción de la IA. Con la creciente preocupación por la privacidad y el mal uso de los datos, está claro que la confianza depende de demostrar un compromiso con la privacidad de los datos y el desarrollo ético de la IA. Las prácticas adecuadas de anonimización de datos fomentan esta confianza, mejorando la transparencia y la credibilidad ante los ojos de los clientes y las partes interesadas por igual. Además, puede brindar a las empresas una ventaja competitiva, especialmente a medida que los consumidores y las empresas se vuelven más exigentes sobre cómo se utilizan sus datos.
Podría interesarle:
Pausa temporal en el desarrollo de IA, ¿está la inteligencia artificial despertando miedo entre los expertos?
La anonimización como imperativo ético
La anonimización no es solo una necesidad legal sino también un imperativo ético. Pangeanic se embarcó en un viaje de anonimización/enmascaramiento de datos hace cinco años cuando la Comisión Europea aprobó su propuesta para desarrollar un software de anonimización multilingüe y de código abierto (Proyecto MAPA). Desde entonces, hemos defendido el concepto de IA ética no solo en el pago justo a los desarrolladores, sino también en el uso de datos personales en la capacitación de IA.
El desarrollo de los sistemas de IA debe guiarse por un firme compromiso con los principios de privacidad, transparencia y equidad. La anonimización de datos proporciona un medio práctico y eficaz de honrar estos principios.
Al incorporar procesos sólidos de anonimización de datos, podemos garantizar que la IA desarrolle todo su potencial de una manera que respete los derechos de privacidad individuales y se adhiera a los estándares éticos. Es un equilibrio difícil de alcanzar, pero crucial para el crecimiento sostenible y responsable de la tecnología de IA.
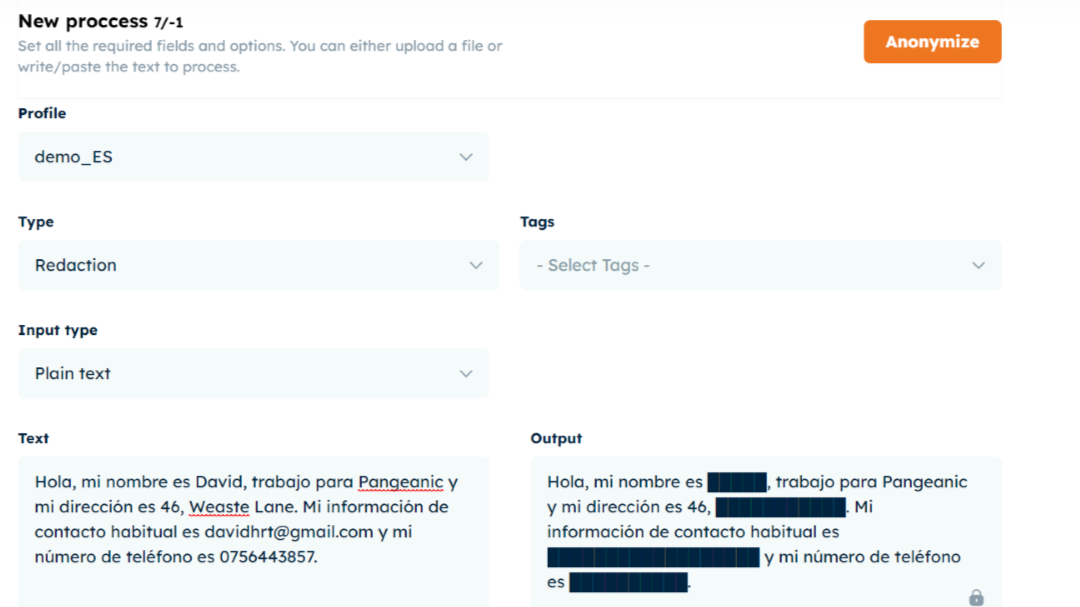
Desde Pangeanic, hemos desarrollado nuestra herramienta de anonimización: Masker.

Masker utiliza la IA para identificar automáticamente la información de identificación personal (PII) y reemplazar los datos confidenciales mediante diferentes tipos de Anonimización. Ajusta el nivel de sensibilidad y elige etiquetas específicas para personalizar la Anonimización de su contenido.
-
Las etiquetas de identificación reemplazan los datos con una etiqueta de datos genérica (por ejemplo, ORG1, NAME2, ADDRESS3)
-
La sustitución reemplaza los datos con un identificador temporal. (p. ej., ACME, JOE, 123 Somewhere St.)
-
Los espacios reemplazan los datos con espacios en blanco.
-
La ofuscación reemplaza los datos con una línea negra continua.
Estos procesos de anonimización de datos están diseñados para minimizar la capacidad de rastreo de datos o rastros electrónicos que puede conducir al uso indebido de datos o revelar detalles personales.
A continuación se muestra un ejemplo de anonimización por ofuscación.