Pangeanic conducted a series of tests with PangeaMT
for specific language domains by combining its own statistical data with data obtained from
TAUS‘s
TDA during late September. The aim of the test was to prove that increased amounts of trustable, regular data from TDA would help Pangeanic’s own technologies to improve output percentage quality, and to open up new domain developments.
Background
Version 1 was a development concerned mainly with technical/engineering, electronics and automotive industries for general, user-manuals and scientific journal publication. Version 2 (PangeaMT) builds on that experience and adds several new areas: Software (SOF), Consumer and Professional Electronics + Computer Hardware (ECH), Marketing-Business-Economics (MBE), Legal-Pro (LEG), Healthcare-Pharma-Life Sciences (HEALTH).
PangeaMT is based on a Moses engine enhanced with an applied set of heuristics according to each language in question. The translation process is fully TMX-based. The concept is to have SMT acting as a plug-in to existing systems, not as an alternative solution or technology. It also integrates a parser that can interpret code/tags in the TMX and place it in the resulting translated segment. Post-editing can take place in any environment, thus resulting in an application-agnostic SMT plug-in.
Machine translation training data
Three domains were selected for the test in the English-Spanish language pair (no distinction as to Lat.Am/EU), with the following number of files:
- ECH (Electronics-Computer Hardware): 800 tmx
- MBE (Marketing-Business-Economics): 76 tmx
- SOF (Software): 80 tmx
Data sets were selected according to the following criteria. a) Language Model to follow b) TDA data availability c) Subject field
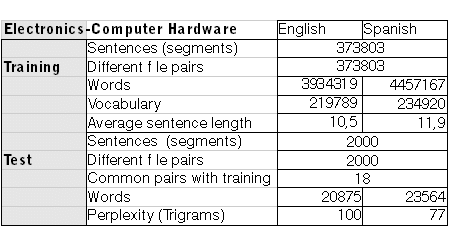
ELECTRONICS – COMPUTER HARDWARE
The aim was to improve on existing engines (Electronics). To this end, TDA data from Intel and Dell in Spanish was added to existing sets coming from Sony. Not all data available from TDA from particular donors was used as fit for the customized training. Some was discarded for a variety of reasons. Client-specific terminology was applied to original donor’s data sets for terminology standardization purposes. Pangeanic contributed with small sets of self-generated data. The result was a medium size 3,9M word engine specifically designed for the field of application and with the client’s terminology applied through donor’s TMX files in order to ease post-editing. The data set for electronics was:

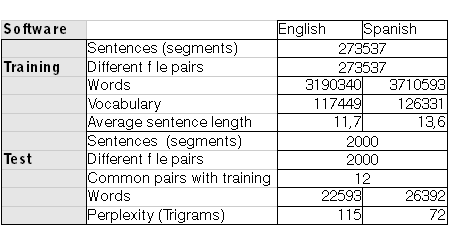
SOFTWARE
The aim of this development was to build a fresh engine with TDA data only in the subject field of a potential client to offer a solution which would show enough ROI for our SMT as a plug-in. To this end, we selected TDA data from several software donors in a subject field related to the product lines. We did not include Microsoft data initially as the size of the TM would have created a bias towards Microsoft terminology. However, engine enhancement is not discarded in future or more general releases. Again, not all data available from TDA from particular donors was used in the customized training. Some data was discarded and Pangeanic contributed with small sets of self-generated data. The data set for software was:

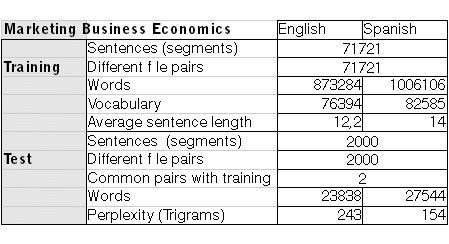
MARKETING-ECONOMICS-BUSINESS
The aim of this development was to build a first test-bench engine serving as a business case within an uncontrolled, general field that has usually been “a work of literature” and out of the scope of traditional MT systems (particularly Rule-Based MT). Marketing and Economics are above natural speech and can be elaborate, complex texts and sometimes flowery or metaphorical. Again, the aim is to offer a solution which would show enough ROI for our SMT as a plug-in. The client did not provide enough training data and TDA did not offer enough bulk related material for this purpose. In this case, to show some results was more essential than to finalize a large engine. The data set for marketing-business-economics was:

Process
The tables below describe the processes followed in the training. We can see that sentence length increases from domain to domain, that 2,000 representative segments (just over 20,000 words in all three cases) were not incorporated in the training so they could be used in the tests (BLEU/Meteor scores). Some sentences happened to be common (identical) to the training (18, 12, 2 respectively) mostly because of the nature of the source files (user manuals, software strings/commands in some cases which contain certain repetitions). Perplexity is a measure that gives us an idea of the complexity of the task and how similar the test is to the training.??The higher the perplexity, the higher the difficulty.



Machine translation training results
Model training + optimization: Moses+MERT Language models: 5-grams TMX files for each category:
Translation results English->Spanish BLEU:
- ECH: 49.98
- MEB: 24.39
- SOF: 47.78
Meteor 0.8.3:
- ECH: 0.4312
- MEB: 0.2610
- SOF: 0.4377
The best scoring domain is Electronics-Computer Hardware, with almost 50% scoring in BLEU and 43 in METEOR. Results in Software are also very high (47,78% and 43,7% respectively). This is a new domain for our development and we have used TDA data almost exclusively. Marketing-Business-Economics lags behind with around 25% in both. Specific, “imaginative” marketing TMs weigh a lot here, and there is less content from TDA. Marketing literature is, by definition, not necessarily as accurate as the other two fields, which are fairly controlled languages. The engine was a first step, a test development still to be enhanced with further data. Nevertheless, the results surpass our expectations. A 50% BLEU-Meteor scoring can translate in large increases in language production. Even the 25%, as an initial result for marketing leaves a lot of room for improvement once even more data is available.