Pangeanic define a IA ética por meio de quatro pilares: transparência, responsabilidade, equidade e confiabilidade, garantindo que os SLM atendam aos...
-1.png)
3 min read
11/07/2023
Vivemos na era da tomada de decisões orientada por dados. Os dados se tornaram o novo petróleo, e os dados pessoais são um dos combustíveis mais refinados. Como resultado, a inteligência artificial (IA) surgiu como uma força transformadora, influenciando profundamente todos os setores, da saúde às finanças e muito mais.
No entanto, o poder da IA vem acompanhado de uma responsabilidade inerente: garantir o uso ético dos dados nos quais ela se baseia. No centro dessa obrigação ética está o conceito de anonimização de dados, um aspecto essencial, mas frequentemente negligenciado, da construção de estruturas éticas de IA.
A anonimização de dados refere-se ao processo de proteção de dados identificáveis para que a privacidade do indivíduo seja preservada enquanto os dados permanecem úteis para análise. Esse processo de desidentificação é fundamental não apenas para cumprir as normas de proteção de dados em evolução, mas também para garantir que o desenvolvimento e a implementação de sistemas de IA sejam eticamente sólidos.
Leitura recomendada:
Redes Neurais: Inteligência Artificial aplicada ao Processamento de Linguagem Natural
Navegando na interseção de privacidade e utilidade
A sofisticação dos algoritmos de IA atualmente significa que uma quantidade sem precedentes de dados é coletada, armazenada, processada e analisada. Embora esses dados sejam fundamentais para aprimorar e adaptar os sistemas de IA, eles suscitam preocupações substanciais com relação à privacidade. Essas preocupações são ampliadas quando os sistemas de IA lidam com dados confidenciais, como registros de saúde, informações de identificação pessoal ou transações financeiras. É nessa interseção de utilidade e privacidade que a anonimização de dados se torna um pilar fundamental na construção de uma IA ética.
Técnicas de anonimização, como pseudonimização, agregação ou criptografia, não apenas protegem a privacidade reduzindo o risco de exposição de dados pessoais, mas também mantêm a utilidade dos dados para os algoritmos de IA. Elas garantem os direitos e as liberdades dos titulares dos dados sem impedir o desenvolvimento e a implantação de sistemas de IA. Quanto mais dados precisarem ser reunidos, coletados e compartilhados entre os sistemas, maior será o risco de que as PII estejam em jogo.
Nós, usuários/consumidores/cidadãos, podemos pensar que não há nada que possamos fazer sobre isso e que a privacidade não existe mais em tempos de smartphones, geolocalização, redes sociais etc. No entanto, os guardiões de nossos dados não podem agir livremente. Existem e devem existir regulamentações que limitem os usos de dados pessoais no treinamento de IA ou que imponham diretamente sua remoção - basicamente porque não sabemos onde nossos dados pessoais podem acabar e quem pode consultá-los.
A perspectiva jurídica: Regulamentos de proteção de dados
Do ponto de vista jurídico, a importância da anonimização de dados não pode ser exagerada. As leis de proteção de dados, como a Lei Geral de Proteção de Dados (GDPR) na União Europeia ou a Lei de Privacidade do Consumidor da Califórnia (CCPA) nos Estados Unidos, impõem regras rígidas sobre como os dados pessoais podem ser processados, e a não conformidade pode resultar em multas e penalidades significativas.
De acordo com essas leis, os dados anônimos não são considerados dados pessoais. Portanto, se a anonimização de dados for executada corretamente, as empresas poderão contornar as complexidades dessas normas e evitar as graves consequências da não conformidade.
No entanto, é fundamental entender que os padrões para o que constitui uma anonimização eficaz são altos, especialmente devido aos recursos dos algoritmos modernos de aprendizado de máquina para potencialmente reidentificar dados anônimos. Portanto, o governo e as empresas devem acompanhar os avanços tecnológicos e os desenvolvimentos legais para garantir que suas técnicas de anonimização estejam em conformidade com a lei e sejam eticamente responsáveis.
Confiança na IA: o papel da anonimização de dados
A confiança é o alicerce da adoção da IA. Com o aumento das preocupações com a privacidade e o uso indevido dos dados, fica claro que a confiança depende da demonstração de um compromisso com a privacidade dos dados e com o desenvolvimento ético da IA. Práticas adequadas de anonimização de dados promovem essa confiança, aumentando a transparência e a credibilidade aos olhos dos clientes e das partes interessadas. Além disso, isso pode dar às empresas uma vantagem competitiva, especialmente à medida que os consumidores e as empresas se tornam mais criteriosos sobre como seus dados são usados.
A anonimização como um imperativo ético
A anonimização não é apenas uma necessidade legal, mas também um imperativo ético. A Pangeanic embarcou em uma jornada de mascaramento/anonimização de dados há cinco anos, quando a Comissão Europeia aprovou sua proposta de desenvolver um software de anonimização multilíngue e de código aberto (Projeto MAPA). Desde então, temos defendido o conceito de IA ética, não apenas no que se refere ao pagamento justo aos desenvolvedores, mas também ao uso de dados pessoais no treinamento de IA.
O desenvolvimento de sistemas de IA deve ser orientado por um compromisso inabalável com os princípios de privacidade, transparência e justiça. A anonimização de dados oferece um meio prático e eficaz de honrar esses princípios.
Ao incorporar processos robustos de anonimização de dados, podemos garantir que a IA realize todo o seu potencial de uma maneira que respeite os direitos individuais de privacidade e adote padrões éticos. É um equilíbrio desafiador, mas crucial para o crescimento sustentável e responsável da tecnologia de IA.
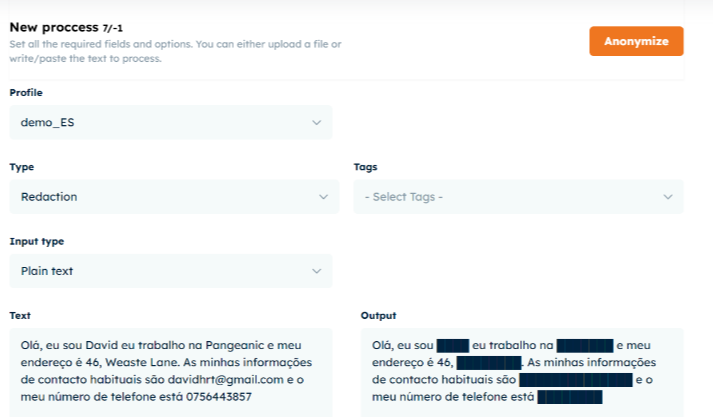
Da Pangeanic, desenvolvemos nossa ferramenta de Masker.
O Masker aproveita o poder da IA para detectar automaticamente informações de identificação pessoal (PII) e substituir dados confidenciais por várias técnicas de anonimização. Adapte o nível de sensibilidade e selecione tags específicas para personalizar o processo de anonimização de acordo com suas necessidades.
- Com tags de ID, os dados são substituídos por tags de dados genéricos (por exemplo, ORG1, NAME2, ADDRESS3).
- A substituição substitui os dados por identificadores temporários (por exemplo, ACME, JOE, 123 Somewhere St.).
- Espaços substituem dados por espaços vazios.
- A ofuscação substitui os dados por linhas pretas sólidas.
Esses métodos de mascaramento de dados são meticulosamente projetados para minimizar o risco de rastrear dados ou trilhas eletrônicas que possam levar ao uso indevido ou à divulgação de informações pessoais.
Aqui está um exemplo de anonimização de dados de redação.